
Hello FollowFox Community!
We are back with SD1.5 fine-tuning posts - the content that has been our most popular content so far.
If you just want the model, download it from Civitai (link).
You might feel that the speed of improvement on Stable Diffusion 1.5 has slowed down or has even peaked. We have a similar feeling; normally, improvements become marginal over time, but we still believe there is plenty of potential left in 1.5-based models. Our team has many ideas and experiments that we want to conduct, so while we are still waiting for further developments on the SDXL front, we decided to fine-tune a few more distilled models in our style.
In this post, we will try to combine everything we have learned so far and describe all the steps that it took us to start from the SD 1.5 model and go to our new cocktail, Cosmopolitan - our newest model that we are implementing on Distillery Discord.
As always, in this post, you will find all the datasets, checkpoints, code, parameters, and thinking we put into the project.
We are back with SD1.5 fine-tuning posts - the content that has been our most popular content so far.
If you just want the model, download it from Civitai (link).
You might feel that the speed of improvement on Stable Diffusion 1.5 has slowed down or has even peaked. We have a similar feeling; normally, improvements become marginal over time, but we still believe there is plenty of potential left in 1.5-based models. Our team has many ideas and experiments that we want to conduct, so while we are still waiting for further developments on the SDXL front, we decided to fine-tune a few more distilled models in our style.
In this post, we will try to combine everything we have learned so far and describe all the steps that it took us to start from the SD 1.5 model and go to our new cocktail, Cosmopolitan - our newest model that we are implementing on Distillery Discord.
As always, in this post, you will find all the datasets, checkpoints, code, parameters, and thinking we put into the project.
The Plan
First, we had to set the goal for this project, which was fairly easy to formulate. The goal was to create a new model that would perform better than our BloodyMary (link), which has proved very powerful (most of the art generated on Distillery is based on BloodyMary mix).
Next, for this iteration, we set a constraint to leverage mostly the things we have learned and realized so far in our journey without introducing too many new variables and going into unknown rabbit holes.
From there, we had to apply this constraint and goal to the usual steps of SD 1.5 model creation that we have formulated here:
- Dataset selection and creation
- Model fine-tuning and choosing candidates
- Mixing our pure alcohol model versions (vodka v1 with v2, and so on)
- Mixing pure version with other trained models to create our Cocktail version such as BloodyMary.
Dataset
In general, we feel good about synthetic datasets (link) and distilling knowledge from the larger models, so we decided to keep this part unchanged and use the Midjourney-based dataset.
If you have seen our Midjourney analytics post (link), that would be our starting point. However, we do not need millions of images, so there was a great opportunity to select a good subset. Our starting dataset (7.7 GB CSV file) is here (link).
Not using the user prompts and labeling the dataset ourselves is an area where we have under-experimented, but that is a massive rabbit hole, and thus, we will decide not to do that now.
However, we had one interesting realization here that led to our decision only to use so-called raw generations from Midjourney. Later, we will find that this didn’t matter much. Still, the theory was that since Mj uses prompt alterations, using user prompts and final output essentially results in the poorly labeled dataset. So, defaulting to a ‘raw’ dataset should address some of it.
For the rest of the decisions, we defaulted to the choices we discussed and found useful in different posts here. Things like users using upscaling mean that the generation was successful. Or that top engaged users are likely to have higher average quality output. And so on. You can see the full notebook (a bit chaotic) we used for the dataset cleaning and downloading here (link).
In the end, we had 11,475 image-text pairs. Unlike previous runs, we decided to split this dataset into training and validation sets ourselves and thus put aside 1,722 images as validation data (15% of all). You can find our full dataset here (link). As you can see, the quality of images in the dataset is superb!
Model Fine-tuning
We decided to use our beloved EveryDream2 Trainer for this task (link), and at this moment, it was a few months since we had done our last ED2 training. And since the ED2 community has never stopped evolving the tool, it meant that there could have been knowledge gaps and rabbit holes for us to face.
To avoid that, we decided to change experimentation at this stage to minimal. Still, we included one that we believe was super important - to train the model at 768p resolution alongside the 512 one.
The original plan was to follow our advice and use Dadaptation (link) to create the first model we would optimize. The plan partially failed as the 768p run kept randomly stopping on Runpod, and after a few retries and many hours lost - we decided to abandon this plan. Instead, we let the 512 version continue with D-Adaptation but switched to the good old AdamW for the 768 version. You can find our 768 fine-tuning config file here (link).
We stopped both training once the validation loss started to trend up consistently. In the case of the 512 model - it happened at about 70 epochs, and for the 768 model, it was after 60 epochs. We were saving checkpoints every ten epochs, so at this point, we had 13 total checkpoints to start with. You can find all of them if you want to test yourself (link for 512 checkpoints) and (link for 768 ones).
The plan here was to select the best checkpoint for each version and proceed to mixing, and we used two inputs to make this call. First - we analyzed the loss graphs, and second, we created XYZ plots to compare outputs.
Loss Graphs
Well, it is obvious that both graphs show that we should have trained a bit less rapidly, but there are a few more interesting observations.

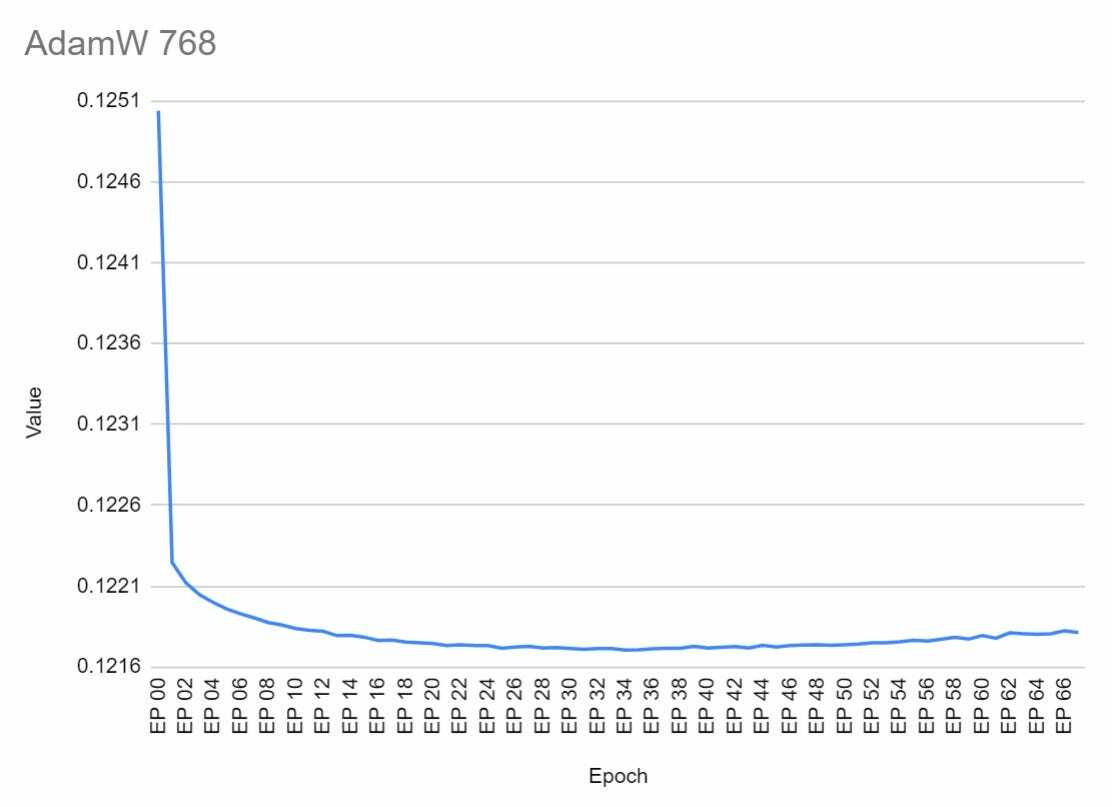
First of all, it is interesting to notice the lower starting loss value (~10% lower, 0.125 vs 0.138) for the higher resolution training even though, in both cases, it is the same training and validation data. We can't make any further conclusions without a closer look at the loss calculation code, but it was interesting to observe.
The 512 model reached the lowest loss value at exactly epoch 40 (the loss value was ~1.4% lower than at the start).
The 768 model reached the lower loss value at epoch 34 (the loss value was ~2.67% lower than at the start). This was interesting to observe - the 768 model started with a lower loss and still ‘improved’ more than the 512 one in absolute terms. This is not a direct comparison but still an interesting observation.
XYZ Grids
We used our ComfyUI API approach (link) as a tool to generate comparison grids. We selected 21 prompts, and since we had two resolutions, we generated each at 512 and 768 resolutions. So, with 42 prompts per model, with four different seeds, that’s 168 images per model, and with 13 checkpoints, we ended up with over 2,000 images generated for the comparisons. You can find all these grids here (the 768 link), (the 512 link).
While familiarizing ourselves with the new generation of models, we were only focused on finding the best checkpoint per resolution for now. Ultimately, we selected Epoch 30 (link) for the 768 version and Epoch 40 (link) for the 512 one.
Mixing Vodka Bases
This mysterious step of mixing our fine-tuned models has proved to us many times to be very successful and impactful, so we decided to do it again.
We took a few hints from our Vodka V4 article (link) and came up with the following mixes:
- 50/50 mix of the 512 version with the 768 one.
- 50% of the 512 with the difference between Vodka V3 and V1
- 50% of the 768 with the difference between Vodka V3 and V1
- 50% of mix 1 (512+768) with the difference between Vodka V3 and V1
You can find all four checkpoints here (link).
Then, we generated more grids. In these grids, we once again used the 42 prompts from earlier, compared the two earlier selected models with the four mixed models, and also added vodka V3 as a comparison point. So, 1,176 more images to compare. (link).
Here, things started to look promising for the 768, and the hybrid versions and mixes 2, 3, and 4 all looked very interesting. So, we decided to proceed to the next step with three out of the four mixes.
Selecting 3rd Party Models as Mixing Candidates
Nowadays, it is widely accepted that mixing different trained checkpoints typically can result in impressive models. And this has proven to be true for our BloodyMary. So, this time, we decided to do more experimentation.
The overall approach here was very similar to our benchmarking post (link), but the last time, we only explored trained models. We wondered if introducing some mixed models as our mix candidates could boost the overall quality. So, we decided to select two sets of candidate models - trained ones and merged ones. For each set, we wanted to find a good realistic model, a good general-purpose model, and, optionally, a bonus interesting model that could be added to the mix. The main goal was to find ingredients that would bring something our Vodka versions lack or do not have. Here are our candidates.
Merged Versions
Trained Models
At this point, you might have guessed, but for all these models, we generated our usual XYZ grids for the 42 prompts to select and design mixes that would turn into Cosmopolitan. You can find all of them here (merge versions link) (trained versions link).
Note that not all of the above models are equally permissive in licensing. We did the tests to see if any of those would stand out even if the license would prohibit further progression of that version. We could learn something interesting. In the end, we ended up with the models that allowed merging.
We created six mix versions in total. Two for each of our vodka resolutions: 512, 768, and the hybrid, as selected earlier. We will create one mix using merged models and one with trained-only models for each. For the merged mix, we decided to do 60% vodka, 20% Realisticvision, and 20% Revanimated. We used 60% Vodka, 20% Epicrealism, and 20% Dreamshaper for the trained mix. Note that the latter recipe is the same as when we did BloodyMary.
You can find all six mixed checkpoints here (link).
Final Selections
The final task was to select one merge from the six candidates. We decided to split this into a two-step process - for step one; we would choose either the merge or trained version as the winner for each of the three resolutions. Then, from the remaining three - we will choose the one.
So, as usual, we started by generating XYZ grids for the six mixes we created (link to grids). We ended up picking models 1.1, 2.2, and 3.1 as winners. So, for 512 and hybrid resolutions - trained mixes won. However, for the 768 - the merged mix had a slight edge.
We generated some more grids for the final test, with the three finalists vs BloodyMary. It was close, but we decided that the flexibility and potential of the hybrid 3.1 version outshined all others. So that is the release version of Cosmopolitan.
You can test the new Cosmopolitan model in Distillery (link) or download and run it yourself from Civitai (link).


Images created with Cosmopolitan
Next Steps and Improvements
Whether or not we will pursue these is a different question, but writing down and documenting ideas that come immediately after this process can be helpful and useful in the future.
First of all, training at 768 and having a high performance at that starting generation had massive implications, so the question is if going further would benefit it even more. I’ve heard that post 768 SD1.5 stops improving, but it might be worth a try.
The 768 graph is too steep - so redoing a run with a more reasonable slope might be worth whatever parameter combinations would get us there.
The mixed model seems to perform the best - this raises the question of even crazier mixes and diverse cocktails.
Finally, reusing this dataset but substituting user prompts with some generated labels is probably the last obvious experiment worth conducting.
If you enjoyed the post, don’t forget to subscribe!
