Hello, FollowFox community!
In today’s post, we will look at a new optimizer making a lot of noise in the community. We have applied this implementation to the Vodka training set and will explore the initial results here.
In today’s post, we will look at a new optimizer making a lot of noise in the community. We have applied this implementation to the Vodka training set and will explore the initial results here.

Just about a month ago, Facebook research published a paper called “Learning-Rate-Free Learning by D-Adaptation” (link) along with the code implementation (link). The paper is very technical but still worth the read regardless of your level. However, what it promises to deliver sounds very exciting and could save a lot of time spent on searching optimal parameters for different datasets and tasks:
D-Adaptation is an approach to automatically setting the learning rate which asymptotically achieves the optimal rate of convergence for minimizing convex Lipschitz functions … the method automatically matches hand-tuned learning rates across more than a dozen diverse machine-learning problems, including large-scale vision and language problems.
It is very exciting to try such new and fresh applications hands-on for practical use cases, but you should also keep in mind that this is cutting-edge stuff, and there are a lot of unknowns. This means that what we achieved today might not be its full potential and capability.
The Plan
The main idea here was to try it and see what happens without too much experimentation and optimization. After the initial try, we can understand where things stand, if we want to dive deeper, and what future experiments could look like.
This new D-Adaptation approach has already been implemented in EveryDream2Trainer (link) by its awesome community, so that is the tool of our choice for this case.
We have been doing a lot of tests recently on our Vodka model series dataset, so that we will reuse those 10k images (link to the dataset).
And finally, the testing plan was to look at log graphs + make the usual visual comparison of the generated images and compare those to the other versions of Vodka models.
Setting up the Training
If you are familiar with ED2 trainer, it is very simple. In train.json, we point the optimizer config to the optimizer_dadapt.json file instead of the usual optimizer file:
"optimizer_config": "optimizer_dadapt.json"
We made minor adjustments to the provided optimizer_dadapt file on the text encoder freezing part (we freeze just 3 layers). As you can see, D-Adaptation (Adam version) is applied to both the text encoder and UNET, and several parameters are set as initial implementation. The paper points out that some of these parameters can significantly impact the training. This means this current setup is very experimental and might not be optimal.
- "optimizer": "dadapt_adam",
- "lr": 1e-1,
- "lr_scheduler": "constant",
- "lr_decay_steps": null,
- "lr_warmup_steps": null,
- "betas": [0.9, 0.999],
- "epsilon": 1e-8,
- "weight_decay": 0.80,
- "d0": 1e-6,
- "decouple": true
We have uploaded all training parameter files on HuggingFace (link) for your convenience.
Training Process and Logs
The first thing we noticed after launching the training was endless logs indicating how the learning rate changes at each step. This is a lot of spam for your console, and I think this will be adjusted in future implementations.
In terms of performance - this implementation is very VRAM-hungry and relatively slow. Here is a comparison with the adam8bit optimizer on the same dataset and mostly the same hyperparameters.

As you can see, D-Adaptation uses almost all 24GB VRAM vs ~14Gb for the adam8bit.

The training speed is also quite a bit slower, ~37 minutes per epoch, as opposed to 27 minutes for the adam8bit.
Loss
We typically train Vodka models for 100 epochs, and with the current parameters, we typically see loss being either flat or declining all the way through. However, with D-Adaptation, we saw loss going up, starting from ~40-45 epochs. Here is the comparison of Vodka V4 (not yet released), where we used the adamw optimizer with the text encoder learning rate of 1.5e-7 and UNET at 5e-8. (Yep, this is the spoiler for the future post).

Interestingly, for V4, we were experimenting with using the adam8bit optimizer and at the same text encoder learning rate of 1.5e-7 and UNET at 5e-8 the two graphs look almost identical.
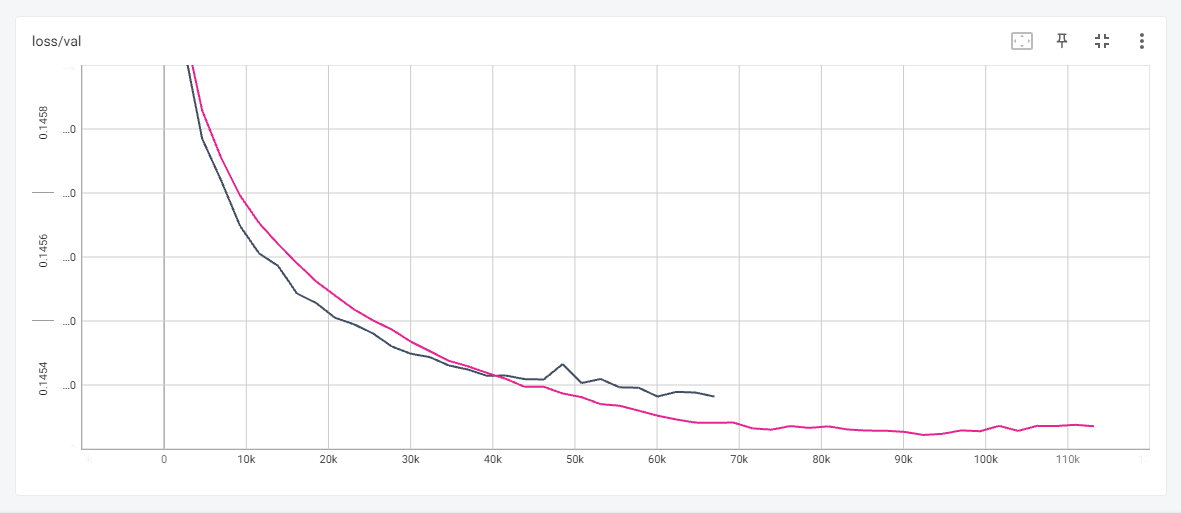
The problem is - V4 with the adam8bit with that loss graph, we were getting a model that looked “cooked” on certain generations.
At the very least, this looks very promising. It got super close to the loss values of a run that can generate a high-quality model with some minor issues. So let’s look at the outputs of the D-Adaptation run and see what we got.
Comparing Outputs
SD 1.5 vs D-Adaptation 25 and 50 epochs
As usual, the first step is to compare the different checkpoints we got after the training. In this case, we stopped training at around 55 epochs as the loss started to go up (we might have done this a bit too early) and got two checkpoints at 25 and 50 epochs.
You can download the two checkpoints from Huggigface (link).
And you can find all full-resolution XYZ grids in the same Huggingface repo (link).

A few very interesting observations:
- Overall, the model looks quite promising. A lot of improvement from 1.5 base, and in general, feels like one of the good Vodka checkpoints
- The problem of feeling ‘burnt’ on realistic generations is still there, possibly even more than usual
- 50 epochs generally look better than the 25 one, indicating that we might have been impatient when stopping at 55.
Vodka v3 75 epochs vs D-Adaptation 50 epochs
The ultimate comparison for this model is to compare with the last known, well-working model. In this case, we selected the initial 75 epochs checkpoint for the release of Vodka v3 (see the post).

Some observations:
- The model looks very close to the V3 - confirming the paper’s claim that it can perform similarly to the hand-picked hyperparameters. This is impressive, considering how much time we have spent getting here.
- The “burnt” level looks identical, meaning that this might be a dataset issue or that we are training on top of the synthetic data. This might also mean that we need to train on suboptimal learning rates and are unsure if D-Adaptation can make that happen.
- While looking similar, the model is not identical, and some generations are quite different. This could mean that the model can be added to the Vodka release versions, adding more quality.
- There are only a handful of such cases, but slightly more deformities when compared to V3. Could be just a bad RNG of seeds.
Ultimately, we decided not to release this version as a standalone Vodka version, but we will keep these checkpoints for potential use in the upcoming blends.
Conclusions and Next Steps
Overall, this was a very worthy and interesting experiment. We got another tool that should be added to our toolkit for future consideration.
D-Adaptation didn’t end up being some insane superpower that magically resolves all our prior problems… but it was magical enough to perform on par with our hand-picked parameters. And that is both impressive and useful.
As the community continues experimenting with it, we expect more discoveries in implementing D-Adaptation optimally and thus improving performance. (Please let us know if you have found a better combination of settings).
Meanwhile, if you have enough VRAM, we suggest trying it. This approach can be especially interesting if you are working with a new dataset - you could create the first baseline model that does well enough to evaluate and plan all other factors.
And finally, we are thinking about partially applying D-Adaptation to our training process. We know that some of the issues we are facing are due to UNET, so we can possibly handle that manually by picking very specific learning rates and, meanwhile, just let D-Adaptation handle the Text Encode.
