We in FollowFox.AI are deeply interested in real world applications to large language models — especially non-trivial ones. We’ve been working in the potential applications of LLMs using commercially-licensed models.
Today, we’ll share with you the results of one of our fintech experiments involving LLaMA, a powerful model licensed for non-commercial use only. While it wasn’t a rigorous statistical study, we believe there is a lot to gain from sharing it as a provocation about the emergent abilities contained in Large Language Models. We believe experiments like these are great to highlight what’s to come.
If helpful, all the (uber simple) code we used in this experiment can be found in Github repository.
Today, we’ll share with you the results of one of our fintech experiments involving LLaMA, a powerful model licensed for non-commercial use only. While it wasn’t a rigorous statistical study, we believe there is a lot to gain from sharing it as a provocation about the emergent abilities contained in Large Language Models. We believe experiments like these are great to highlight what’s to come.
If helpful, all the (uber simple) code we used in this experiment can be found in Github repository.
Provocation for this post
Let’s start with the basic provocation for this exercise.
LLMs work by receiving textual information provided to them in a prompt, and then spitting out a continuation of that prompt that (hopefully) makes sense. An LLM discovers what can be an acceptable output by means of its training, which, in the case of LLaMA, involved exposing the models to texts containing several hundreds of billions of words. The training led the LLM to know the frequencies of transitions between one word and another, and it’s that knowledge that is used by the LLM to generate textual outputs — a random seed, in conjunction with the frequencies of transitions, leads the LLM to choose a chain of output words that has a great potential to produce logically sound sentences.
At their core, then, LLMs are next-word prediction engines, but they may be much more than that. LLMs generalize the rules that bind words to each other based off of large swaths of texts they digested in the training phase, a process which — for a sufficiently powerful and well-designed LLM — might lead to logical inference as an emergent ability.
A paper from last October, “Emergent Abilities of Large Language Models”, dives deep into the topic of emergent abilities, stating that “The ability to perform a task via few-shot prompting is emergent when a model has random performance until a certain scale, after which performance increases to well-above random.”
We intend to check if LLaMA is better than random chance in the task of approving credit card applications, by inferring whether to approve them or not via few-shot prompting. To do so, we will show LLaMA a “low risk” and a “bad risk” example, and then we will ask it to decided whether an applicant is either “low risk” or “bad risk”.
Our ultimate objective is to answer the question: can LLaMA infer the rules to evaluate credit card applications, and perform better than a simple flip of a coin? — or, more simply: is approving credit cards an emergent ability of LLaMA?
First things first — how to access LLaMA through an API?
Building on top of our previous post on installing LLaMA in old GPUs, we will be using Oobabooga’s text-generation-webui through its API to run our experiments, which will be run in Python. To start the API, we just need to start the webui’s API service by adding the parameter --api to the command line when starting the webui. Specifically, substitute your “python3 server.py” command line to this one:
Let’s start with the basic provocation for this exercise.
LLMs work by receiving textual information provided to them in a prompt, and then spitting out a continuation of that prompt that (hopefully) makes sense. An LLM discovers what can be an acceptable output by means of its training, which, in the case of LLaMA, involved exposing the models to texts containing several hundreds of billions of words. The training led the LLM to know the frequencies of transitions between one word and another, and it’s that knowledge that is used by the LLM to generate textual outputs — a random seed, in conjunction with the frequencies of transitions, leads the LLM to choose a chain of output words that has a great potential to produce logically sound sentences.
At their core, then, LLMs are next-word prediction engines, but they may be much more than that. LLMs generalize the rules that bind words to each other based off of large swaths of texts they digested in the training phase, a process which — for a sufficiently powerful and well-designed LLM — might lead to logical inference as an emergent ability.
A paper from last October, “Emergent Abilities of Large Language Models”, dives deep into the topic of emergent abilities, stating that “The ability to perform a task via few-shot prompting is emergent when a model has random performance until a certain scale, after which performance increases to well-above random.”
We intend to check if LLaMA is better than random chance in the task of approving credit card applications, by inferring whether to approve them or not via few-shot prompting. To do so, we will show LLaMA a “low risk” and a “bad risk” example, and then we will ask it to decided whether an applicant is either “low risk” or “bad risk”.
Our ultimate objective is to answer the question: can LLaMA infer the rules to evaluate credit card applications, and perform better than a simple flip of a coin? — or, more simply: is approving credit cards an emergent ability of LLaMA?
First things first — how to access LLaMA through an API?
Building on top of our previous post on installing LLaMA in old GPUs, we will be using Oobabooga’s text-generation-webui through its API to run our experiments, which will be run in Python. To start the API, we just need to start the webui’s API service by adding the parameter --api to the command line when starting the webui. Specifically, substitute your “python3 server.py” command line to this one:
python3 server.py --wbits 4 --groupsize 128 --model_type LLaMA --xformers --apiIf you’re using our WSL distribution, you should see something like this in your WSL terminal:
Figure 1. Starting up Oobabooga’s text-generation-webui API.
Now, you’ll be able to access via code the server on the :5000 and :5005 ports. We will be using the streaming server by means of using the following code in Python:
import websockets
import asyncio
import json
HOST = 'localhost:5005'
URI = f'ws://{HOST}/api/v1/stream'
async def run(context):
request = {
'prompt': context,
'max_new_tokens': 10,
'do_sample': True,
'temperature': 1.99,
'top_p': 0.18,
'typical_p': 1,
'repetition_penalty': 1.15,
'top_k': 30,
'min_length': 5,
'no_repeat_ngram_size': 0,
'num_beams': 1,
'penalty_alpha': 0,
'length_penalty': 1,
'early_stopping': False,
'seed': -1,
'add_bos_token': True,
'truncation_length': 510,
'ban_eos_token': True,
'skip_special_tokens': True,
'stopping_strings': []
}
async with websockets.connect(URI) as websocket:
await websocket.send(json.dumps(request))
yield context
while True:
incoming_data = await websocket.recv()
incoming_data = json.loads(incoming_data)
match incoming_data['event']:
case 'text_stream':
yield incoming_data['text']
case 'stream_end':
returnThis code is passing to text-generation-webui all generative parameters — namely the prompt (variable context) as well as the parameters inside text-generation-webui’s ‘Parameters’ tab —, and receives back the textual output as the LLM generates it.
We hardcoded the parameters above to match with text-generation-webui’s “NovelAI-Sphinx Moth” preset, which is a preset that uses high temperature and low top_p parameters. We found that this combination worked well to constrain outputs to generate less noise.
We find text-generation-webui’s API to be a great way to experiment with small LLMs. On top of being extremely simple to use — just calling the function run(context) above generates the LLM results based on the prompt it ingests —, it’s very easy to experiment with different models as you can just log in to the webui on its :7860 port and switch between the models. Also, since we’re using Textgen’s platform to run the model, this allows us to run 4-bit quantized models and/or use attention optimizations like --xformers (which mostly increases token output per second) or --sdp-attention (good at reducing max VRAM use) simply by changing the python3 server.py call.
We hardcoded the parameters above to match with text-generation-webui’s “NovelAI-Sphinx Moth” preset, which is a preset that uses high temperature and low top_p parameters. We found that this combination worked well to constrain outputs to generate less noise.
We find text-generation-webui’s API to be a great way to experiment with small LLMs. On top of being extremely simple to use — just calling the function run(context) above generates the LLM results based on the prompt it ingests —, it’s very easy to experiment with different models as you can just log in to the webui on its :7860 port and switch between the models. Also, since we’re using Textgen’s platform to run the model, this allows us to run 4-bit quantized models and/or use attention optimizations like --xformers (which mostly increases token output per second) or --sdp-attention (good at reducing max VRAM use) simply by changing the python3 server.py call.
Experiment setup and design
The dataset we used comes from the textbook “Econometric Analysis” by NYC Professor William Greene, and are available on Kaggle here. It contains real data from 1319 credit card applications from a US institution in the early 1990s. The dataset contains 12 data columns:
The dataset was lopsided towards approving credit card applicants — 78% of the entries had a “yes” on its “card” column. For reference, the first 20 instances of the dataset are shown below.
The dataset we used comes from the textbook “Econometric Analysis” by NYC Professor William Greene, and are available on Kaggle here. It contains real data from 1319 credit card applications from a US institution in the early 1990s. The dataset contains 12 data columns:
- card: “yes” if application for credit card was accepted, “no” if not
- reports: Number of major derogatory reports the applicant has received
- age: age of applicant, in n years plus twelfths of a year
- income: applicant’s yearly income, in US dollars divided by 10,000
- share: ratio of credit card expenditure to yearly income
- expenditure: average monthly credit card expenditure
- owner: “yes” if applicant owns their home, “no” if rent
- selfemp: “yes” if applicant is self-employed, “no” if otherwise
- dependents: number of dependents the applicant has
- months: total months the applicant has lived at current address
- majorcards: number of major credit cards held by applicant
- active: number of active credit accounts held by applicant
The dataset was lopsided towards approving credit card applicants — 78% of the entries had a “yes” on its “card” column. For reference, the first 20 instances of the dataset are shown below.
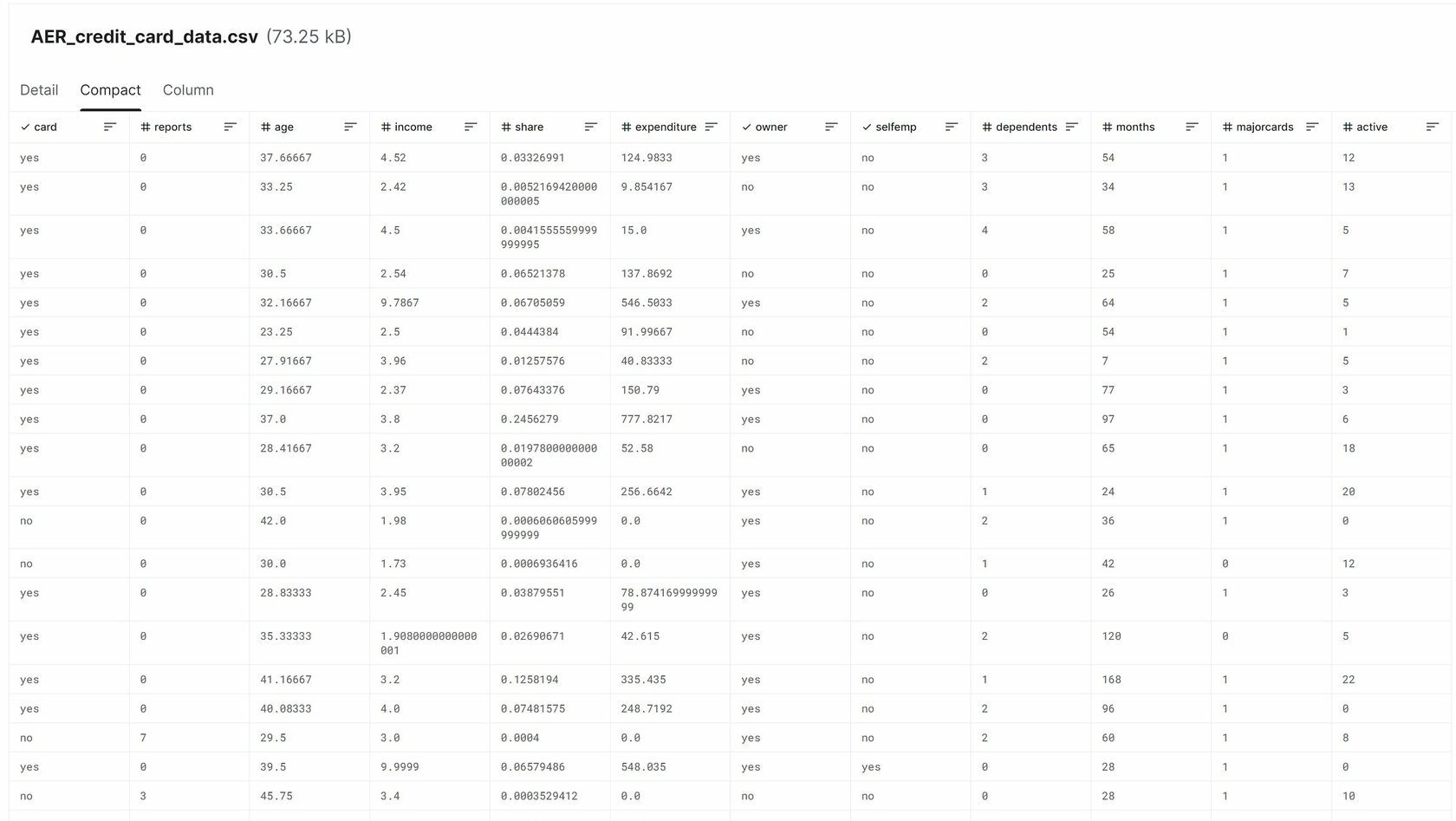
Figure 2. First 20 instances contained in the dataset in Kaggle.
The first step of the experiment was to consolidate all information but the “card” column in one sentence template which will be used as input for LLaMA. For example, the first instance on the table above was fully consolidated into the following sentence:
The applicant is 38 years old, has 0 major derogatory reports, earns an annual income of $45200, has a share ratio of 3% of credit card expenditure to yearly income, spends an average of $125 per month on their credit card, does not own their home, is not self-employed, has 3 dependents, has lived at their current address for 54 months, holds 1 major credit cards, and has 12 active credit accounts.
This is easily done via code or on Excel since this is a small dataset, but you can find it here the dataset containing the preprocessed sentence under the column ‘text’ (it’s also posted in the github repository). Once this step was done, we could proceed to create the prompt to feed into our run(context) function defined above.
We used a ‘few-shot prompting’ strategy to run our experiment. This meant we first provided the LLM with examples of how it should respond, and then we gave it an instance of the dataset to which it should respond. As such, for each of the 1319 instances of the dataset, we ran a prompt as per the following example:
The applicant is 38 years old, has 0 major derogatory reports, earns an annual income of $45200, has a share ratio of 3% of credit card expenditure to yearly income, spends an average of $125 per month on their credit card, does not own their home, is not self-employed, has 3 dependents, has lived at their current address for 54 months, holds 1 major credit cards, and has 12 active credit accounts.
This is easily done via code or on Excel since this is a small dataset, but you can find it here the dataset containing the preprocessed sentence under the column ‘text’ (it’s also posted in the github repository). Once this step was done, we could proceed to create the prompt to feed into our run(context) function defined above.
We used a ‘few-shot prompting’ strategy to run our experiment. This meant we first provided the LLM with examples of how it should respond, and then we gave it an instance of the dataset to which it should respond. As such, for each of the 1319 instances of the dataset, we ran a prompt as per the following example:

Figure 3. Example of few-shot prompt given to the LLM.
As shown above, we provided to the LLM two examples, one of a ‘low risk’ applicant and another one of a ‘high risk’ applicant. (We define ‘low risk’ as any applicant who receives a credit card in the dataset — that is, an applicant whose ‘card’ column is labeled ‘yes’ in the dataset —, and ‘high risk’ if otherwise.) These examples were randomly-drawn from the data table and the order in which these examples were shown was randomized too, so as to minimize biases towards/against words closest to the output text.
We guaranteed that the LLM would only ingest this prompt (and forget anything else it wrote before) by setting the truncation_length in the run(context) function to a number (510) just above the maximum tokens that the prompt can represent. The LLM then proceeded to write between 5 and 10 tokens in the yellow part.
Finally, once the LLM provided us with its response, we then tested if the response was valid by filtering it through the following rules:
If the result was deemed invalid, then the model was rerun until a valid result (that is, a text that complies with rules #1 to #3 above) was achieved. The end result were sentences that declared the LLM’s opinion on whether the applicant was “low risk” or “high risk”, while resorting only to 2 examples and its own inference abilities to generate its conviction. If the LLM declared that the applicant was “low risk”, then we would assume that the applicant would receive a credit card; if the applicant was deemed “high risk”, then the credit card would be denied.
We ran this experiment for the full dataset, using 6 different LLaMA models: the base models LLaMA-7B, LLaMA-13B and LLaMA-30B, as well as instruction-finetuned versions of each of them (Vicuna-1.1-7B, Vicuna-13B-Free, and Alpaca-30B).
We guaranteed that the LLM would only ingest this prompt (and forget anything else it wrote before) by setting the truncation_length in the run(context) function to a number (510) just above the maximum tokens that the prompt can represent. The LLM then proceeded to write between 5 and 10 tokens in the yellow part.
Finally, once the LLM provided us with its response, we then tested if the response was valid by filtering it through the following rules:
- Only results containing the words “high” or “low” could be accepted;
- Results containing both words “high” and “low” would be discarded;
- Results containing initial list markers like “1.”, “A.” or “a)” would be discarded too, so as to avoid accepting responses that would merely list the possible alternatives.
If the result was deemed invalid, then the model was rerun until a valid result (that is, a text that complies with rules #1 to #3 above) was achieved. The end result were sentences that declared the LLM’s opinion on whether the applicant was “low risk” or “high risk”, while resorting only to 2 examples and its own inference abilities to generate its conviction. If the LLM declared that the applicant was “low risk”, then we would assume that the applicant would receive a credit card; if the applicant was deemed “high risk”, then the credit card would be denied.
We ran this experiment for the full dataset, using 6 different LLaMA models: the base models LLaMA-7B, LLaMA-13B and LLaMA-30B, as well as instruction-finetuned versions of each of them (Vicuna-1.1-7B, Vicuna-13B-Free, and Alpaca-30B).

Figure 4. Image of our code running.
How we evaluated the results
Since we are dealing with a dataset that is heavily biased towards “low risk” applicants, evaluating the results is less obvious that one may first realize; given its natural bias, simply calculating the number of results that the models got right and dividing by the number of estimations doesn’t give us much of a signal. (Just imagine a model that doesn’t evaluate anything and just assigns “low risk” to all the applicants — given that 78% of them did receive a credit card in real life, that metric would indicate a 78% accuracy, which is hardly informative regarding the model performance.)
To tackle this, we took inspiration from machine learning models such as those aimed classifying malignancy among tumors (malignant tumors are less common than benign ones), presented in this Google ML course link. Once the generation of text was finished, we then created the metrics to evaluate the experiment; for each AI model, we created the summary matrix below in order to understand its performance metrics:
Since we are dealing with a dataset that is heavily biased towards “low risk” applicants, evaluating the results is less obvious that one may first realize; given its natural bias, simply calculating the number of results that the models got right and dividing by the number of estimations doesn’t give us much of a signal. (Just imagine a model that doesn’t evaluate anything and just assigns “low risk” to all the applicants — given that 78% of them did receive a credit card in real life, that metric would indicate a 78% accuracy, which is hardly informative regarding the model performance.)
To tackle this, we took inspiration from machine learning models such as those aimed classifying malignancy among tumors (malignant tumors are less common than benign ones), presented in this Google ML course link. Once the generation of text was finished, we then created the metrics to evaluate the experiment; for each AI model, we created the summary matrix below in order to understand its performance metrics:

Figure 5. Evaluation matrix built for every AI model run.
This table is a simple way to display all four possible states of an evaluation:
Using these numbers, we then calculate the following metrics that indicate the model’s performance, all of which must be evaluated together to establish the adequacy of the models:
We did these calculations for all models, as well as for the random chance case — a 50/50 flip of a coin for every application — with the intent to discover whether any of the models are superior to random chance as a decision model.
Results and Evaluation
The table below summarizes all the results. Lots of numbers there; our discussion over them follows below.
- A True Positive (TP) is when the model says “high risk”, and the card column says “no” (TP);
- A True Negative (TN) is when the model says “low risk” and the card column says “yes” (TN);
- A False Positive (FP) is when the model says “high risk”, but the card column says “yes” (FP);
- A False Negative (FN) is when the model says “low risk”, but the card column says “no” (FP).
Using these numbers, we then calculate the following metrics that indicate the model’s performance, all of which must be evaluated together to establish the adequacy of the models:
- Precision: the proportion of “high risk” decisions made by the AI that were actually correct, calculated as:
- Precision = TP/(TP + FP)
- Recall: the proportion of real-life “high risk” applicants that were identified correctly, calculated as:
- Recall = TP/(TP + FN)
- Accuracy: the proportion of predictions that our model got right, calculated as:
- Accuracy = (TP + TN) / (TP + FP + FN + TN)
We did these calculations for all models, as well as for the random chance case — a 50/50 flip of a coin for every application — with the intent to discover whether any of the models are superior to random chance as a decision model.
Results and Evaluation
The table below summarizes all the results. Lots of numbers there; our discussion over them follows below.
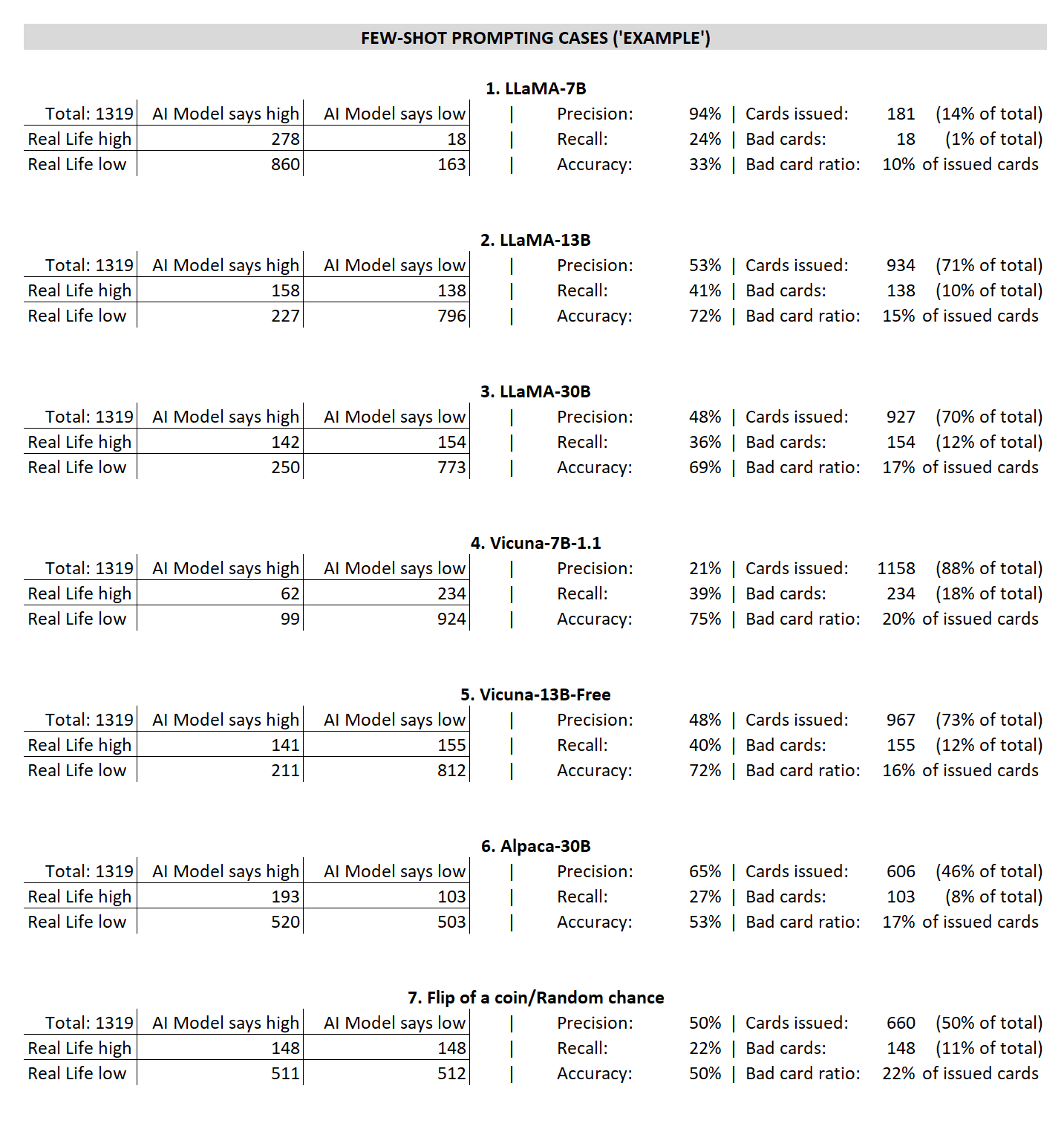
Figure 6. Results for the Few-Shot experiment. High or low refer to whether the applicant is deemed “high risk” or “low risk” by the model. Only low risk applicants receive credit cards.
We can draw 3 particularly interesting conclusions from the results above:
1.The smaller-sized (7 billion parameter) models cannot be deemed better than random chance.
LLaMA-7B is too conservative and ends up issuing very little cards. Vicuna-7B-1.1 seems to err on the other way, being too permissive and having a much lower precision than the random chance scenario despite keeping a similar bad card ratio (number of bad cards issued, divided by the number of cards issued).
2.Instruction-finetuning doesn’t seem to improve much on the model performance.
Vicuna-13B-Free behaves very similarly to its base model LLaMA-13B, while both Vicuna-7B-1.1 and Alpaca-30B display different, but arguably worse, results than its base models. The instruction training also worked in conflicting ways, with Vicuna-7B-1.1 being much more permissive than its base model LLaMA-7B, and Alpaca-30B being much more restrictive than its base model LLaMA-30B.
While there is a lot of noise here, it is interesting to note that Vicuna-13B-Free, which had performance on par with its base model, is the only model we used that was finetuned over an uncensored instruction dataset — both Vicuna-7B-1.1 and Alpaca-30B have a lot of censored content (responses like “I’m sorry, but as a large language model I cannot discuss controversial issues…” etc).
3.(and this can be a big deal!) The larger base models (13 billion and 30 billion parameters) are likely better than random chance.
LLaMA-13B and LLaMA-30B are much more accurate and exhibit much better recall than random chance, even while having a similar precision level. They issue more credit cards even while keeping the number of bad cards at about the same level as the random chance scenario. What’s more, there doesn’t seem to be a significant difference between them.
In conclusion
Recalling again the definition of an emergent ability as per the paper we cited before:
“The ability to perform a task via few-shot prompting is emergent when a model has random performance until a certain scale, after which performance increases to well-above random.”
So let me summarize our initial finding in a full sentence. If true, it would be a big deal:
LLaMA models of size 13B or above might have developed an emergent ability to infer a response that is better than random chance in a few-shot prompting strategy in the task of evaluating credit card approvals.
In simpler terms, what we are saying is: if you provide LLaMA-13B — a general-purpose, foundational LLM — with a few examples of credit card applications and then ask it whether to approve an application or not, then its decision is likely better than a flip of a coin. This is a big deal because LLaMA-13B is completely untrained for this task, and this may be an emergent behavior of LLaMA as it scaled beyond to 13 billion parameters and beyond.
There are tons of caveats in this conclusion, obviously. This is not a rigorous statistical study — the dataset is a toy one, being very small (1319 instances) and old; we have run the models only a few times, so even their results need to be further tested; etc. But what’s important in this experiment is that it outlines the potential for LLMs to be used as general-purpose inference machines. With additional finetuning, its results can surely improve, perhaps even to be a prediction method on par with typical methods such as specialized machine learning models or multivariate regression.
We will continue this exploration in a few more posts in the near future, as we continue our investigations on the applications of large language models. Stay tuned!
1.The smaller-sized (7 billion parameter) models cannot be deemed better than random chance.
LLaMA-7B is too conservative and ends up issuing very little cards. Vicuna-7B-1.1 seems to err on the other way, being too permissive and having a much lower precision than the random chance scenario despite keeping a similar bad card ratio (number of bad cards issued, divided by the number of cards issued).
2.Instruction-finetuning doesn’t seem to improve much on the model performance.
Vicuna-13B-Free behaves very similarly to its base model LLaMA-13B, while both Vicuna-7B-1.1 and Alpaca-30B display different, but arguably worse, results than its base models. The instruction training also worked in conflicting ways, with Vicuna-7B-1.1 being much more permissive than its base model LLaMA-7B, and Alpaca-30B being much more restrictive than its base model LLaMA-30B.
While there is a lot of noise here, it is interesting to note that Vicuna-13B-Free, which had performance on par with its base model, is the only model we used that was finetuned over an uncensored instruction dataset — both Vicuna-7B-1.1 and Alpaca-30B have a lot of censored content (responses like “I’m sorry, but as a large language model I cannot discuss controversial issues…” etc).
3.(and this can be a big deal!) The larger base models (13 billion and 30 billion parameters) are likely better than random chance.
LLaMA-13B and LLaMA-30B are much more accurate and exhibit much better recall than random chance, even while having a similar precision level. They issue more credit cards even while keeping the number of bad cards at about the same level as the random chance scenario. What’s more, there doesn’t seem to be a significant difference between them.
In conclusion
Recalling again the definition of an emergent ability as per the paper we cited before:
“The ability to perform a task via few-shot prompting is emergent when a model has random performance until a certain scale, after which performance increases to well-above random.”
So let me summarize our initial finding in a full sentence. If true, it would be a big deal:
LLaMA models of size 13B or above might have developed an emergent ability to infer a response that is better than random chance in a few-shot prompting strategy in the task of evaluating credit card approvals.
In simpler terms, what we are saying is: if you provide LLaMA-13B — a general-purpose, foundational LLM — with a few examples of credit card applications and then ask it whether to approve an application or not, then its decision is likely better than a flip of a coin. This is a big deal because LLaMA-13B is completely untrained for this task, and this may be an emergent behavior of LLaMA as it scaled beyond to 13 billion parameters and beyond.
There are tons of caveats in this conclusion, obviously. This is not a rigorous statistical study — the dataset is a toy one, being very small (1319 instances) and old; we have run the models only a few times, so even their results need to be further tested; etc. But what’s important in this experiment is that it outlines the potential for LLMs to be used as general-purpose inference machines. With additional finetuning, its results can surely improve, perhaps even to be a prediction method on par with typical methods such as specialized machine learning models or multivariate regression.
We will continue this exploration in a few more posts in the near future, as we continue our investigations on the applications of large language models. Stay tuned!
