
When we launched Distillery a few months ago, we made a promise to always be transparent with our methods, and to be committed to the open source cause. This post aims to make true on this promise by disclosing the unsexy part of Distillery: its back-end.
In this post, we will go through the following topics:
In this post, we will go through the following topics:
- We’ll teach you how to build a Discord bot running Stable Diffusion in 15 minutes or less;
- We’ll then go through all the fragilities that a simple bot like that needs to address;
- We’ll then disclose how we did address them in Distillery;
- Finally, we’ll dive into the actual cloud architecture we are using, involving AWS, Runpod and Reyki AI as our cloud partners.
Let’s begin.
It takes less than 15 minutes to set up a Discord Stable Diffusion bot (here’s how)
Distillery’s raison-d'être is very simple to describe: in Discord, receive a command /serve containing a user prompt, and then return the image outputs from a Stable Diffusion instance. The schema below is how the interface should present itself to the user.

Naturally, there’s a lot going on that’s represented by the left-right arrow.
Here’s a way to get started, following these conceivable steps:
1.To create a Discord slash command, first there must be a bot that creates it. To create it, an application must be created in the Discord Developer Portal.
a.Once created, click on it, click on “Bot” and turn on “Server Members Intent” and “Message Content Intent”.
b.Finally, click on “OAuth2”, then on “URL Generator”, then in the “bot” scope. Select at least the “Send Messages” and “Read Messages/View Channels” permissions. Then, copy and go to the url generated in the bottom part of the screen to add the bot to a Discord server you are an admin of.
2.After creating the bot, you must then create code that connects it to the bot you created. You could, for instance, adapt this code we open-sourced if you’d like to create one using Python – this code was the prototype of our Distillery bot.
3.After creating and coding the bot, you must then install a Stable Diffusion, say, by using the uber popular Automatic1111, making sure it runs as an API service.
This is simple enough. Assuming you already run Automatic1111, you could just run it with the added --api parameter, then run the bot.py code in another terminal, and done – with less than 200 lines of code and 15 minutes or less of effort, you now are a proud owner of a generative AI art bot in Discord.
Here’s a way to get started, following these conceivable steps:
1.To create a Discord slash command, first there must be a bot that creates it. To create it, an application must be created in the Discord Developer Portal.
a.Once created, click on it, click on “Bot” and turn on “Server Members Intent” and “Message Content Intent”.
b.Finally, click on “OAuth2”, then on “URL Generator”, then in the “bot” scope. Select at least the “Send Messages” and “Read Messages/View Channels” permissions. Then, copy and go to the url generated in the bottom part of the screen to add the bot to a Discord server you are an admin of.
2.After creating the bot, you must then create code that connects it to the bot you created. You could, for instance, adapt this code we open-sourced if you’d like to create one using Python – this code was the prototype of our Distillery bot.
3.After creating and coding the bot, you must then install a Stable Diffusion, say, by using the uber popular Automatic1111, making sure it runs as an API service.
This is simple enough. Assuming you already run Automatic1111, you could just run it with the added --api parameter, then run the bot.py code in another terminal, and done – with less than 200 lines of code and 15 minutes or less of effort, you now are a proud owner of a generative AI art bot in Discord.
If, however, you wish to run an scalable system, you’ll soon understand the limitations of this approach:
When you task yourself with dealing with these issues, you’ll soon get into a rabbit hole that can become incredibly deep. You’ll need to work on some of that internet magic we’ve grown to depend on and love, called DevOps.
- Requires a fully dedicated server. This approach necessitates a dedicated PC running 100% of the time, so this can be very expensive and wasteful.
- No parallel requests. Images are made on a first-come, first-served basis, coming from the GPU of the machine you installed the bot script; this makes queuing time be directly proportional to the number of requests sent before your request. Even if you have a fleet of machines ready for use, you’ll need to create some load balancing logic and the means for delivery of the images to Discord without disruptions.
- No workflow flexibility. As it is, the bot expects a prompt and a negative prompt, and that’s it. Any other workflow will necessitate direct changes in the code: if you’d like to change models, or do image-to-image, or do controlnet, etc.
- No redundancies. If anything breaks, as they often do, you’ll have pure downtime. Also, there’s no such thing as a ‘failing gracefully’ in this approach – any failure will leave the system hanging and will require a human being re-running the code to bring it back online.
- Bandwidth issues. Assuming the PC running the backend runs on-premises, any connectivity hiccups can kill the bot. Also, bandwidth and latency themselves might be a limitation if the number of requests is high enough.
- No content checks. Anything that is requested to the bot gets relayed to Automatic1111, regardless of the request content or which user is making the request, and its results get sent back to Discord. Illegal requests or content that goes against Discord’s rules would not be blocked.
When you task yourself with dealing with these issues, you’ll soon get into a rabbit hole that can become incredibly deep. You’ll need to work on some of that internet magic we’ve grown to depend on and love, called DevOps.

This post aims to explain our take on the internet magic that makes Distillery run. Its intended audience is of generative AI enthusiasts who’d like to create something similar but are beginners to the field of DevOps. With it, we aim to fulfill the promises of being transparent with our methods and committed to the open source cause.
How Distillery addresses these issues
In order to be able to service several requests in parallel, even while avoiding having a fleet of dedicated servers, we opted to run our service using a provider of serverless GPU endpoints. A ‘serverless’ setup allows for the use of (and payment for) a fraction of the time of a GPU running in the cloud, as opposed to renting/owning a machine in full. This resolved points (1) and (2) on the list above.
In order to tackle the workflow flexibility issue — point (3) above —, we opted to use ComfyUI as a backend. ComfyUI is extremely fast and extensible, and it allows us to design any number of workflows with ease. Its main difficulty lies in its weird approach to an API: it needs to receive a JSON file containing the full workflow it must run in order to generate an image. In order to make it work in a serverless environment, we created and open-sourced ComfyUI-Serverless, a connector that can be used to automatically start ComfyUI, deliver the payload to it, and then deliver the output images to the requestor.
In order to tackle the lack of redundancies — point (4) above —, we chose to run all our processes in containerized form, that are automatically reset if something breaks their runs. To ensure that the system keeps running even if one of its components fails, we decided to split the back-end processes in three types:
We also run multiple instances of each component: we currently run 3 instances (or “shards”, in Discord parlance) of the Bot and 5 concurrent instances of the Master. We had to be careful in our code to avoid situations where concurrent instances race against each other — for instance, to ensure that each request is processed only one single time, we used a caching server that locks each request to the first Bot that asks for it.
Running the services on the cloud, in a high-bandwidth environment, using reputable providers resolved point (5).
Finally, by being very careful on the Bot code dealing with parsing and preprocessing of commands, we can minimize the risks of forbidden content — point (6) above — being generated.
With all this said, we can now show the schematic workflow of our current version, v0.2.9 Izarra. As stated before, internet magic, it seems, can get complicated really fast:
How Distillery addresses these issues
In order to be able to service several requests in parallel, even while avoiding having a fleet of dedicated servers, we opted to run our service using a provider of serverless GPU endpoints. A ‘serverless’ setup allows for the use of (and payment for) a fraction of the time of a GPU running in the cloud, as opposed to renting/owning a machine in full. This resolved points (1) and (2) on the list above.
In order to tackle the workflow flexibility issue — point (3) above —, we opted to use ComfyUI as a backend. ComfyUI is extremely fast and extensible, and it allows us to design any number of workflows with ease. Its main difficulty lies in its weird approach to an API: it needs to receive a JSON file containing the full workflow it must run in order to generate an image. In order to make it work in a serverless environment, we created and open-sourced ComfyUI-Serverless, a connector that can be used to automatically start ComfyUI, deliver the payload to it, and then deliver the output images to the requestor.
In order to tackle the lack of redundancies — point (4) above —, we chose to run all our processes in containerized form, that are automatically reset if something breaks their runs. To ensure that the system keeps running even if one of its components fails, we decided to split the back-end processes in three types:
- A process that runs the script for the bot, controlling the interaction between the back-end and the Discord front-end (the “Bot”);
- A process that controls the inferencing jobs (the “Master” process);
- A process that executes the inferencing itself (the “Worker” processes).
We also run multiple instances of each component: we currently run 3 instances (or “shards”, in Discord parlance) of the Bot and 5 concurrent instances of the Master. We had to be careful in our code to avoid situations where concurrent instances race against each other — for instance, to ensure that each request is processed only one single time, we used a caching server that locks each request to the first Bot that asks for it.
Running the services on the cloud, in a high-bandwidth environment, using reputable providers resolved point (5).
Finally, by being very careful on the Bot code dealing with parsing and preprocessing of commands, we can minimize the risks of forbidden content — point (6) above — being generated.
With all this said, we can now show the schematic workflow of our current version, v0.2.9 Izarra. As stated before, internet magic, it seems, can get complicated really fast:

In simpler terms, a successful request should follow the journey below:
The most important part of our workflow is the Master/Worker relationship. It’s a 1-to-N relationship, meaning that there can be only one Master, but there can be several Workers at any given time. Also, the fact that the Master is separated from the Bot front-end makes Distillery ready to receive and service direct API requests in the near future.
How Distillery works, in practice
With the workflow defined, it’s time to get to the specifics.
To run Distillery, we contract the services of three cloud providers: AWS, which host the backbone of our service; Runpod, which runs Stable Diffusion and does the inferencing work; and Reyki AI, our cloud cost optimization partner (more on Reyki AI in a moment).
- A user in Discord sends a /serve request.
- The Bot parses the request, and then creates a payload containing the ComfyUI API workflow in JSON format. The Bot then pushes the payload into a data table called “Generation Queue”.
- The Master pops the Generation Queue and retrieves the payload, sending it to the serverless GPU endpoint. The serverless GPU endpoint will create a Worker container to process the request.
- A Worker receives the payload, generates images, saves them in a cloud storage, and delivers the pointers to the output images back to the Master.
- The Master receives the output images’ pointers and then pushes them to a data table called “Send Queue”.
- The Bot pops the Send Queue, retrieves the output images’ pointers, downloads the images, and then sends them back to the requestor user in Discord.
The most important part of our workflow is the Master/Worker relationship. It’s a 1-to-N relationship, meaning that there can be only one Master, but there can be several Workers at any given time. Also, the fact that the Master is separated from the Bot front-end makes Distillery ready to receive and service direct API requests in the near future.
How Distillery works, in practice
With the workflow defined, it’s time to get to the specifics.
To run Distillery, we contract the services of three cloud providers: AWS, which host the backbone of our service; Runpod, which runs Stable Diffusion and does the inferencing work; and Reyki AI, our cloud cost optimization partner (more on Reyki AI in a moment).

AWS Lightsail as Distillery’s backbone
It’s notoriously difficult to find your way around AWS’ constellation of services. We took a long time to figure out what could be the simplest configuration of AWS services that could satisfy our design requirements. We ultimately chose to use AWS Lightsail as the platform to launch Distillery. AWS Lightsail acts as a simplified, mini-AWS, much more straightforward to use than any other AWS service we considered. (Seriously. It took us more time to figure out how to use AWS Cloudwatch, which is just a logging service, than it took us to deploy everything else we do in AWS Lightsail. I wished someone told me about AWS Lightsail when I first started learning how to run things in the cloud.)
Excluding the GPU inferencing itself, and a few minor details, Distillery runs entirely inside containers in AWS Lightsail, using a storage solution (called S3) offered inside of Lightsail, and using a MySQL database managed also managed under AWS Lightsail. Other, minor, components of the AWS architecture include the beforementioned AWS Cloudwatch for as a log server, AWS Elastic Container Repository (ECR) to store the container images, and AWS Memcached as a caching server to make sure the redundant containers don’t get in conflict with each other.
Runpod as our GPU inferencing partner
We’ve been using Runpod as our cloud compute partner for most of our explorations. We chose to deploy in Runpod in light of their excellent UI, their competitive prices for serverless GPUs, and finally, due to the ability to design our own worker container (a practice aptly called “bring-your-own-container” in the industry). Those reasons, together with the great working relationship we developed with their team, made us keep them as our main GPU partner to this day.
We had a lot of bugs with the connections to Runpod in the first months running Distillery, but these were largely resolved by a combination of updates on Runpod’s end, and bugfixes on our own code. Our worker now runs reliably well, and we welcome anyone to use it — you can find the open-source code here. Our workers run in machines with Nvidia RTX A6000 GPUs, and we are ready to have up to 60 of them working concurrently.
The main issue we’ve been having with Runpod is the availability of free GPUs for serverless inferencing. While this is arguably a result of how successful they were in attracting new customers, it has become a potentially limiting factor in our service’s growth, so are looking to add a second inferencing service, AWS Sagemaker, to our system.
Reyki AI as our cost optimization partner
AWS’ bill, especially as we onboard AWS Sagemaker, can be very expensive if not managed properly, and AWS’ opaque pricing scheme makes us especially concerned. To address that, we hired Reyki AI.
Reyki AI is an excellent idea that, in our view, should become the industry standard in managing cloud computing costs. Reyki AI's solutions automate the process of managing cloud infrastructure, ensuring that organizations get the most value out of their cloud investments.
They’ve built quite an amazing product that uses machine learning to predict our cloud use, and then allocates to Distillery the best available rates for the type of computing service we require at any given moment. While this is already important for Distillery now, it will be of utmost importance at scale, when using AWS Sagemaker as a serverless GPU provider.
Again, we absolutely loved Reyki AI and the concept behind it. If you’re building anything cloud-based, you should consider having them as a partner. They work with the main cloud providers (AWS, Google and Azure), so it’s very likely they can be useful.
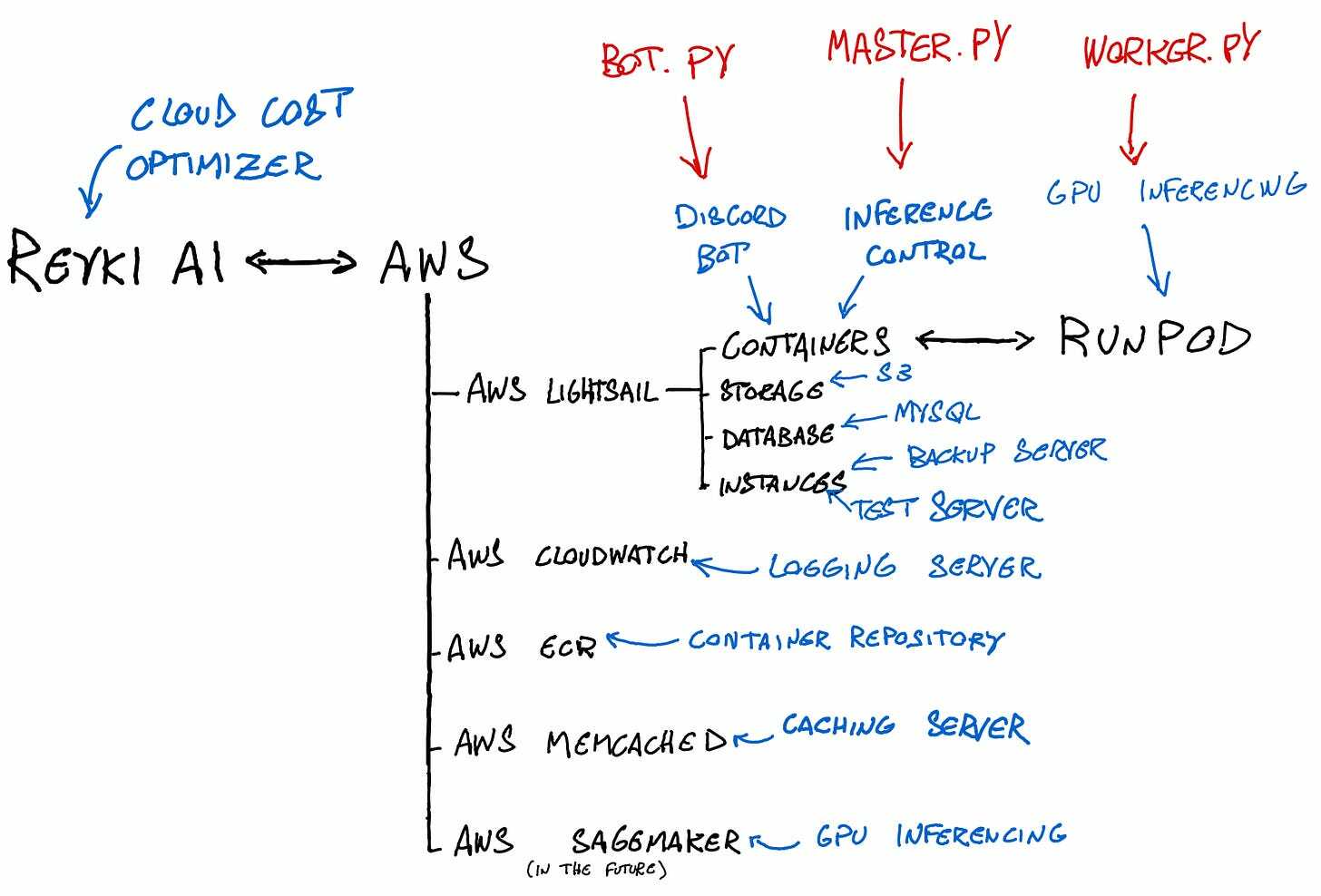
In summary
The image below is a summary of how Distillery is run.
As of today, 3 containers running a bot.py script, and 5 containers running a master.py script, are hosted inside AWS Lightsail container service. These scripts make use of several services inside AWS such as file storage, MySQL database, logging and caching, in order to operate a Discord bot and to control the GPU inferencing done by a script called worker.py hosted in Runpod; in the near future, we will also add AWS Sagemaker as a source for GPUs — all the while having Reyki AI as our main tool to rein in and optimize costs.
It’s notoriously difficult to find your way around AWS’ constellation of services. We took a long time to figure out what could be the simplest configuration of AWS services that could satisfy our design requirements. We ultimately chose to use AWS Lightsail as the platform to launch Distillery. AWS Lightsail acts as a simplified, mini-AWS, much more straightforward to use than any other AWS service we considered. (Seriously. It took us more time to figure out how to use AWS Cloudwatch, which is just a logging service, than it took us to deploy everything else we do in AWS Lightsail. I wished someone told me about AWS Lightsail when I first started learning how to run things in the cloud.)
Excluding the GPU inferencing itself, and a few minor details, Distillery runs entirely inside containers in AWS Lightsail, using a storage solution (called S3) offered inside of Lightsail, and using a MySQL database managed also managed under AWS Lightsail. Other, minor, components of the AWS architecture include the beforementioned AWS Cloudwatch for as a log server, AWS Elastic Container Repository (ECR) to store the container images, and AWS Memcached as a caching server to make sure the redundant containers don’t get in conflict with each other.
Runpod as our GPU inferencing partner
We’ve been using Runpod as our cloud compute partner for most of our explorations. We chose to deploy in Runpod in light of their excellent UI, their competitive prices for serverless GPUs, and finally, due to the ability to design our own worker container (a practice aptly called “bring-your-own-container” in the industry). Those reasons, together with the great working relationship we developed with their team, made us keep them as our main GPU partner to this day.
We had a lot of bugs with the connections to Runpod in the first months running Distillery, but these were largely resolved by a combination of updates on Runpod’s end, and bugfixes on our own code. Our worker now runs reliably well, and we welcome anyone to use it — you can find the open-source code here. Our workers run in machines with Nvidia RTX A6000 GPUs, and we are ready to have up to 60 of them working concurrently.
The main issue we’ve been having with Runpod is the availability of free GPUs for serverless inferencing. While this is arguably a result of how successful they were in attracting new customers, it has become a potentially limiting factor in our service’s growth, so are looking to add a second inferencing service, AWS Sagemaker, to our system.
Reyki AI as our cost optimization partner
AWS’ bill, especially as we onboard AWS Sagemaker, can be very expensive if not managed properly, and AWS’ opaque pricing scheme makes us especially concerned. To address that, we hired Reyki AI.
Reyki AI is an excellent idea that, in our view, should become the industry standard in managing cloud computing costs. Reyki AI's solutions automate the process of managing cloud infrastructure, ensuring that organizations get the most value out of their cloud investments.
They’ve built quite an amazing product that uses machine learning to predict our cloud use, and then allocates to Distillery the best available rates for the type of computing service we require at any given moment. While this is already important for Distillery now, it will be of utmost importance at scale, when using AWS Sagemaker as a serverless GPU provider.
Again, we absolutely loved Reyki AI and the concept behind it. If you’re building anything cloud-based, you should consider having them as a partner. They work with the main cloud providers (AWS, Google and Azure), so it’s very likely they can be useful.
In summary
The image below is a summary of how Distillery is run.
As of today, 3 containers running a bot.py script, and 5 containers running a master.py script, are hosted inside AWS Lightsail container service. These scripts make use of several services inside AWS such as file storage, MySQL database, logging and caching, in order to operate a Discord bot and to control the GPU inferencing done by a script called worker.py hosted in Runpod; in the near future, we will also add AWS Sagemaker as a source for GPUs — all the while having Reyki AI as our main tool to rein in and optimize costs.
Our hope is that this post can help enthusiasts in their journey to learn how to deploy an AI system in a scalable way. If you are interested in deploying something similar, and want to exchange ideas with us, we will be glad to talk!
And if you’d like to check Distillery, you can do so by following this link.
And if you’d like to check Distillery, you can do so by following this link.
